2023. 7. 5. 23:29ㆍjpa
경로 표현식이란?
select m.username -> 상태 필드
from Member m
join m.team t -> 단일 값 연관 필드
join m.orders o -> 컬렉션 값 연관 필드
where t.name ='팀A'
경로 표현식 용어 정리
상태 필드 : 단순히 값을 저장하기 위한 필드
연관 필드 : 연관관계를 위한 필드
단일 값 연관 필드 : @XXXtoOne : 대상이 엔티티
컬렉션 값 연관 필드 : @XXXtoMany : 대상이 컬렉션
상태 필드 : 경로 탐색의 끝, 탐색 x
단일 값 연관 경로 : 묵시적 내부 조인 발생, 탐색 가능
select m.team.name from Member m; //team에서 경로탐색이 더 가능하다(name)
컬렉션 값 연관 경로 : 묵시적 내부 조인 발생, 탐색 불가능
from 절에서 명시적 조인을 통해 별칭을 얻으면 별칭을 통해 탐색 가능
실무에서는 명시적 조인을 사용하자.
jpql(java persistence query language) - 페치 조인
- sql 조인 종류는 아니고 jpa에서 제공하는 기능이다.
- jpql에서 성능 최적화를 위해 제공하는 기능
- 연관된 엔티티나 컬렉션을 sql 한 번에 함께 조회하는 기능
- join fetch 명령어 사용
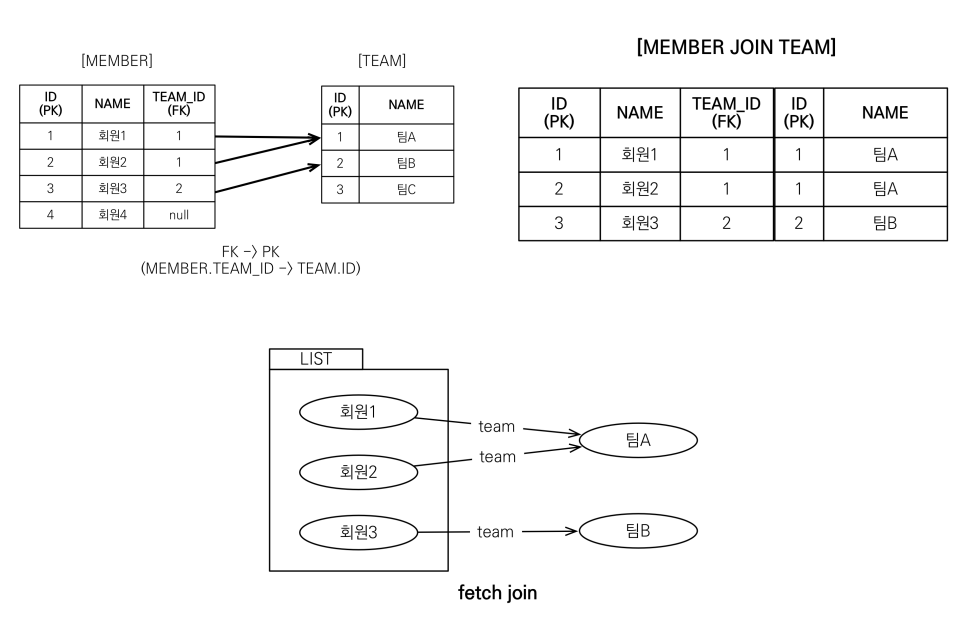
엔티티 페치 조인
회원을 조회하면서 연관된 팀도 함께 조회(sql 한번에)
//JPQL
select m from Member m join fetch m.team
//SQL
select m.* t.* from Member m inner join Team t on m.team_id = t.id;
String jpql = "select m from Member m join fetch m.team";
List<Member> members = em.createQuery(jpql, Member.class)
.getResultList();
for (Member member : members) {
//페치 조인으로 회원과 팀을 함께 조회해서 지연 로딩X
System.out.println("username = " + member.getUsername() + ", " +
"teamName = " + member.getTeam().name());
}
페치조인을 사용하면 실제 엔티티가 담겨 지연로딩 없이 바로 사용이 가능하다.
페치 조인 사용시
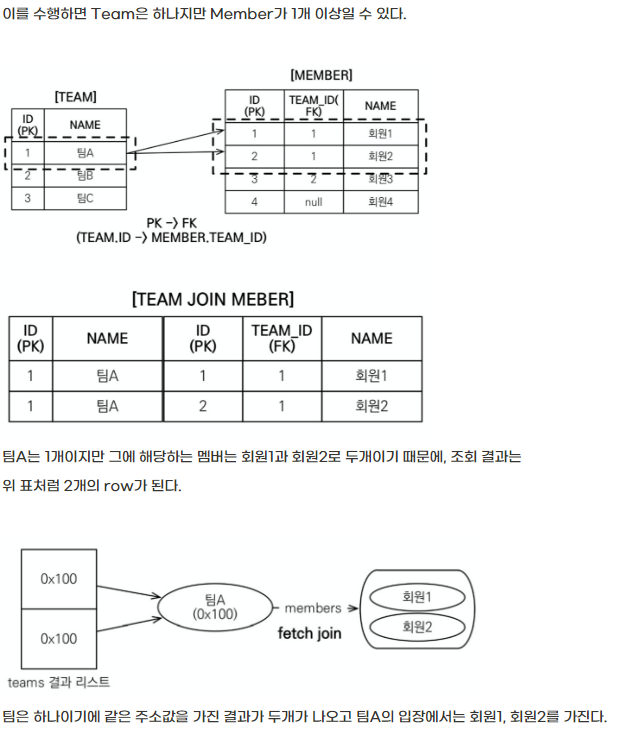
일대다 관계(컬렉션 페치 조인)을 사용시 데이터가 뻥티기가 될 수 있다.
//JPQL
select t from Team t join fetch t.members where t.name = '팀A';
//SQL
select t.*, m.* from team t, inner join member m on t.id = m.team_id
where t.name = '팀A';
String query = "select t from Team t";
String query2 = "select t from Team t join fetch t.members";
List<Team> result = em.createQuery(query, Team.class).getResultList();
List<Team> result2 = em.createQuery(query2, Team .class).getResultList();
System.out.println("result size::"+ result.size()); //2
System.out.println("result2 size::"+ result2.size());//3
일대다 관계에서는 join fetch 결과로 팀A는 하나지만 Row는 2개로 뻥튀기된다.
반대로 다대일은 뻥튀기 되지 않는다.
페치 조인의 한계
- 페치 조인 대상에는 별칭을 줄 수 없다. (하이버네이트 가능하지만 사용하지 말자)
String query = "select t from Team t join fetch t.members as m"
//as m 이라는 별칭(alias)는 fetch join에서 사용할 수 없다.
- 둘 이상의 컬렉션은 페치 조인 할 수 없다.
String query = "select t from Team t join fetch t.members, t.orders"
//불가능 fetch join에서 컬렉션은 1개만 사용하자.
- 컬렉션을 페치 조인하면 페이지 api를 사용할 수 없다.
String query = "select t from Team t join fetch t.members";
List<Team> result = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(1)
.getResultList();
경고 로그를 남기고 매우 위험하니 사용하면 안된다.
해결방안
일대다를 다대일로 방향을 전환하여 해결!
String query = "select m from Member m join fetch m.team t";
엔티티 직접 사용
기본키 값
jpql에서 엔티티를 직접 사용하면 sql에서 해당 엔티티의 기본키 값을 사용한다.
//JPQL
select count(m.id) from Member m //엔티티의 아이디를 사용
select count(m) from Member m //엔티티를 직접 사용
//SQL(JPQL 둘 다 같은 다음 SQL 실행)
select count(m.id) as cnt from Member m
파라미터를 엔티티를 넘기나 식별자를 넘겨주더라도 실행된 sql은 같다.
/*엔티티를 파라미터로 전달*/
String jpql = "select m from Member m where m = :member";
List resultList = em.createQuery(jpql)
.setParameter("member", member)
.getResultList();
/*식별자를 직접 전달*/
String jpql = "select m from Member m where m.id = :memberId";
List resultList = em.createQuery(jpql)
.setParameter("memberId", memberId)
.getResultList();
위의 두 jpql의 실행 sql은 아래와 동일하다.
select m.* from Member m where m.id = ?
외래키 값
기본키와 로직은 동일하다. 엔티티 혹은 외래키를 쓰면 실행 sql은 동일하다.
Team team = em.find(Team.class, 1L);
String query = "select m from Member m where m.team = :team";
List resultList = em.createQuery(query)
.setParameter("team", team)
.getResultList();
String query = "select m from Member m where m.team.id = :teamId";
List resultList = em.createQuery(query)
.setParameter("teamId", teamId)
.getResultList();
실행된 sql은 동일하다.
select m.* from Member m where m.team_id = ?
Named 쿼리
- 미리 정의해서 이름을 부여해두고 사용하는 jpql
- 정적쿼리
- 어노테이션, xml에 정의하고 사용
@Entity
@NamedQuery(
name="Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}
...
List<Member> resultList = em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();
애플리케이션 로딩 시점에 초기화 후 재사용
-> jpa는 결국 sql로 파싱되어 사용되는데 로딩 시점에 초기화가 된다면 파싱 비용을 절약 가능하다.
namedQuery 예시
@Repository
public interface MemberRepository extends JpaRepository<Member, Long>{
@Query("select u from User u where u.username = ?1")
Member findByUsername(String username);
}
벌크 연산
쿼리 한번으로 여러 테이블을 업데이트한다.
벌크 연산 주의
영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리
해결 방법
1. 벌크 연산을 먼저 실행
2. 벌크 연산 수행 후 영속성 컨텍스트를 초기화한다.
'jpa' 카테고리의 다른 글
| 프록시와 연관관계 정리 (0) | 2023.06.25 |
|---|---|
| h2 테이블 삭제 안되는 오류 - maven (0) | 2023.06.24 |
| jpa - 고급매핑 정리 (0) | 2023.06.24 |
| jpa - 다양한 연관관계 매핑 (0) | 2023.06.24 |
| jpa 연관매핑 기초 - 단방향, 양방향 (0) | 2023.06.22 |